Reproduced with the permission of the Journal of Legal Studies. This is based on the version on my hard disk, and may differ in detail from the published version.
David Friedman *
It is apparent from the effort and time required to try these 160 cases, that unless this plan or some other procedure that permits damages to be adjudicated in the aggregate is approved, these cases cannot be tried. Defendants complain about the 1% likelihood that the result would be significantly different. However, plaintiffs are facing a 100% confidence level of being denied access to the courts. The Court will leave it to the academicians and legal scholars to debate whether our notion of due process has room for balancing these competing interests.--Judge Robert Parker, Cimino v Raymark
In Cimino v. Raymark,0 Judge Parker of the Eastern District of Texas implemented a radical solution to the problem of litigating mass torts. Instead of conducting individual trials for several thousand plaintiffs, he selected a random sample of 160 of them, tried their cases, and based the awards given to the remaining plaintiffs on the outcome of those trials. In defending the procedure against the charge that it deprived the parties of due process, he argued that if he had instead required individual trials, most of the cases would never have been resolved.
The procedure of Cimino was explained and defended in a 1992 article by Michael J. Saks & Peter David Blanck.[1] The purpose of this essay is not to dispute either their views or those of Judge Parker, but rather to suggest a further step along the same path. The procedure of aggregation and sampling implemented in Cimino does a reasonably good job of estimating the total damages that the defendants would have paid if every case had been tried separately,[2] and does so at a cost much lower than that of individual trials. It does a much poorer job of allocating that total among the plaintiffs. My proposal is intended to solve that problem.
In part I of this article I explain the procedure used by Judge Parker in Cimino, the improvements suggested by Saks and Blanck, and the limitations of the procedure, even with such improvements. Part II describes my proposal for generating an estimate of the relative claims of the plaintiffs and incorporating that estimate into the procedure. Part III considers the legal status of the modified procedure, arguing that it is in some ways more defensible than the version implemented in Cimino. Part IV discusses potential problems, both those implicit in the original idea of aggregation and sampling and additional ones created by my proposed modifications. Part V suggests ways in which the procedure I suggest could be extended beyond the context of class actions. Part VI describes the results of the application of the procedure to an explicit formal model; the mathematics are presented in an appendix. Part VII summarizes my conclusions.
If the Court could somehow close thirty cases a month, it would take six and one-half years to try these cases and there would be pending over 5,000 untouched cases at the present rate of filing.--Judge Parker in Cimino
Cimino v. Raymark went to trial as a class action with 2,298 plaintiffs and five defendants. The trial consisted of three phases. In Phase I, a set of issues common to all plaintiffs and defendants were resolved.[3] Phase II apportioned causation among the defendants and determined which plaintiffs had had sufficient exposure to asbestos, based on each plaintiff's workplace and craft, for such exposure to be a producing cause of an asbestos-related injury or disease.[4]
The purpose of Phase III was to determine damages. Instead of trying all cases, the court divided the plaintiffs into five categories, according to which asbestos related disease each suffered from. A random sample was drawn from each category; the sample was larger for categories with more plaintiffs.[5] The sample cases were tried. Plaintiffs in the sample received the damages that they were awarded. Plaintiffs not in the sample received the average of the damages awarded to the tried cases in their category.
Judge Parker argued that the result was fair to the defendants, since the total amount awarded was an accurate estimate of the total that would have been awarded if all cases had been tried. He cited confidence levels ranging from 95% to 99%, but did not explain what those numbers meant or what assumptions were used to calculate them.
The situation is not quite so clear as Judge Parker apparently believed. The statistical conclusions reported, if correct, depend on assumptions about the distribution of the awards that would be produced by jury trial. It is possible to describe distributions consistent with the observed data for which the result of even as large a sample as was used in Cimino would be a very imprecise measure of the total damages that would be awarded. With such a distribution, the expected result of the Cimino procedure would still be correct: if the procedure were repeated a large enough number of times, the average outcome would be very close to the result of trying every case separately. But the probability that the result produced by the Cimino procedure would be substantially different from the result of trying all cases might be much larger than implied by the confidence levels cited by the judge.[6] This suggests that it might be worth looking for a procedure superior to random sampling.
Even if, as Judge Parker argues, the procedure is fair to the defendants, there remains the question of whether it properly allocates the damage payment among the individual plaintiffs. The procedure used in Cimino does not do so, as Judge Parker himself conceded.[7] He dealt with that problem by obtaining the plaintiffs' assent in advance. In future litigation involving such procedures, however, the question will be important for at least five reasons.
1. Many people regard justice as part of what litigation is supposed to produce. If a procedure collects the right amount of damages but gives them to the wrong people, or to the right people but in the wrong amounts, it is not just.
2. One purpose of some of the legal rules that determine damages, such as contributory negligence, is to affect the incentives of potential plaintiffs. In Cimino, some plaintiffs whose cases were tried received no damages, possibly because their decision to smoke was regarded by the jury as contributory negligence.[8] The effect of such verdicts was to reduce the award given to all plaintiffs in the same disease category whose cases were not tried, smokers and non-smokers alike. So the use of the procedure undercuts the effectiveness of such a legal rule.
3. In order for a class to be certified, the judge must find that the representative parties will fairly and adequately protect the interests of the class.[9] A procedure which predictably awards some plaintiffs more than they would get from trying their case themselves and others less may not meet the requirement.
4. Even if the class is certified, individual members are free to withdraw. A procedure that predictably awards some plaintiffs less than they would receive at trial gives such plaintiffs an incentive to withdraw from the class, which reduces the benefit both of the class action and of the procedure.[10]
5. In awarding the right amount of damages to the wrong people, the Cimino procedure resembles fluid recovery. Under fluid recovery, where it is difficult to identify the members of the plaintiff class and determine how much of the award each is entitled to, money awarded to the plaintiffs is instead used to benefit a group of people similar to those who were injured. That approach has been seriously questioned by the courts.[11]
For all of these reasons, it is desirable to construct procedures that approximate the correct result among plaintiffs as well as between plaintiffs and defendants. In Cimino, Judge Parker attempted to do so in two ways. Phase II of the trial was designed to eliminate from the case defendants whose exposure to asbestos was not a producing cause of an asbestos related injury or disease. In Phase III, defendants were grouped according to the particular sort of injury or disease they had suffered, presumably because individuals suffering from the same disease would have some tendency to be owed the same damages.
Both of these are very imprecise ways of allocating damage payments to individual plaintiffs. Saks and Blanck offer two additional possibilities. One is to use statistical analysis to define groups with common characteristics. The other is to construct a linear model relating damages to characteristics and then use trial results to estimate the parameters of the model.[12]
While these procedures can improve on the simple approach of giving every plaintiff the same amount or the slightly more complicated approach implemented in Cimino, they suffer from a common problem. It is neither obvious in advance nor uncontroversial what characteristics are relevant to the damage award or how they are related. Even if we knew the characteristics, there is no reason to assume the relation is linear.[13] As statisticians are aware, the same data can be fit with a multitude of different specifications. If, after trying a few thousand, the court finds one that happens to fit the tried cases fairly well, that should not give us much confidence that it will also fit the untried cases.
What we need is not a procedure for dividing the damage award among the plaintiffs-the best way of doing that will almost certainly vary from case to case. What we need is a procedure that makes it in the interest of someone to figure out, for any particular case, what the correct division among the plaintiffs in that case is. Part II describes one such procedure.
I define the strength of a plaintiff's case as the average of what would be awarded if it were tried many times by many separate juries; I call this average verdict (for plaintiff i) <Di>. The objective of the procedure is to produce a damage award of about <Di> for each defendant i, at a cost much lower than the cost of trying every case many times, or even trying every case once.
By examining the facts relevant to an individual plaintiff i, an investigator can estimate the value of <Di>. The more resources are spent on the investigation, the more accurate the estimate will be. This is true both for an individual investigator and for a judge or jury calculating an award in the course of a trial. I assume the cost to a competent individual investigator of estimating <Di> is much lower than the cost to a jury, since the investigator is a specialist in such investigations, is an individual rather than a committee, and is not limited by the elaborate procedural rules that control court trials. [15]
We start with a group of N plaintiffs represented by an attorney. The procedure is as follows:
Step 1: The plaintiffs' attorney produces, for each plaintiff i, a claim Ci. Ci is the amount the attorney claims that plaintiff i ought to receive in damages. For reasons that will become clear below, it will be in the attorney's interest to make Ci proportional to his estimate of <Di>.
Step 2: The plaintiffs' attorney gives his list of claims Ci to the defendant's attorney.
Step 3: The defendant's attorney selects from the list a small number of cases to be tried. For simplicity in exposition, assume that ten cases are to be selected and that the cases selected turn out to be those of plaintiffs 1-10.
These cases are tried. The court awards damages Di to each of the ten plaintiffs.
Step 4: The court calculates R=(D1/C1+D2/C2+... D10/C10)/10, and awards damages of RxCi to each of the N plaintiffs.
Under this procedure, it should be possible to resolve the N cases much more cheaply than with N separate trials. Only ten cases actually have to be litigated. All plaintiffs have their damages estimated, but the estimate is made for everyone else by the plaintiffs' attorney.
Why does the procedure generate actual damages for
plaintiff i close to <Di>? Consider
the situation first from the standpoint of the defense attorney at
Step 3. He wants to select plaintiffs whose claims
Ci are large relative to
<Di>, the amount a court would, on average,
award them. By selecting plaintiffs who have overclaimed, he produces
a low value of R and thus reduces the total amount (![]() )his
client must pay in damages.
)his
client must pay in damages.
Next consider the situation from the standpoint of the plaintiffs' attorney at step 1. Because he knows that the defense attorney will try to select for trial plaintiffs with a high ratio of Ci to <Di>, he maximizes the total payments his clients receive by trying to make the ratio the same for all clients. The simplest way of doing so is to set Ci equal to his estimate of <Di> for each client.[16] So the amount claimed for each plaintiff will be equal to his attorney's estimate of what he can expect to get at trial.[17]
The award received by a particular plaintiff may deviate from what he ought to receive for two reasons: The court may give the wrong verdicts for the cases tried, or the plaintiffs' attorney may claim the wrong amount for a particular plaintiff. Since ten cases are tried separately and their results averaged, the first source of error should be much smaller than if each plaintiff's case had been tried by itself.[18] Since the attorney can estimate <Di> much less expensively than a court, the second source of error can be made smaller than it would be with an actual trial, while still keeping litigation expenses (including the expense of making such estimates) well below those of individual trials. So it should be possible to produce a more accurate verdict at lower cost under this procedure than with individual trials. The cost is higher than with the Cimino procedure, since additional costs are born by the plaintiffs' attorney in making claims and the defendant's attorney in choosing cases to litigate. But this procedure, unlike that one, generates separate results for each plaintiff proportioned to the strength of each plaintiff's case.
The procedure as I have described it makes sense for a hundred plaintiffs, for a thousand, perhaps for more. In Cimino, the information actually collected included medical evaluations for about 1,400 of the 2,298 plaintiffs who eventually went to trial, so much of the research required by my suggested procedure had actually been done. But it makes less sense for the sort of class action that involves a very large number of plaintiffs, most with very small claims. In such a case, evaluating each plaintiff's case in order to decide how much to claim for him might cost more than the total damages awarded.
One approach to such a situation would be to allow the plaintiffs' attorney to state Ci for classes of plaintiffs rather than for individual plaintiffs. Thus he might claim that each heavy smoker born before 1960 was entitled to $10, each light smoker born between 1960 and 1970 to $2, .... The defendant's attorney would select classes for trial; individual cases would be selected from those classes at random. Such a variant on the procedure might be appropriate in situations where individual claims are low and separate estimates for each case thus unreasonably expensive.
A more sophisticated approach would combine the procedure described here with an idea suggested by Saks and Blanck.[19] Instead of producing a claim for each plaintiff, the plaintiffs' attorney produces a statistical model showing how he believes that the amount each plaintiff is entitled to should depend on the characteristics of the plaintiff. The defendant's attorney specifies a sampling protocol, describing how plaintiffs are to be selected for trial based on their characteristics. The court then selects plaintiffs for trial at random, subject to the constraints of the sampling protocol. The verdicts for those plaintiffs are used to estimate the parameters of the model, and awards for all plaintiffs are calculated accordingly.
In the simplest version of this, the plaintiffs' attorney would specify the entire model save for one multiplicative parameter. If, for example, he believed that the amount awarded ought to depend linearly on the age of the plaintiff and the number of years he had worked at a site using asbestos, he might offer the model:
Damages = A[$100,000 - $1,000 x Age in Years+ $10,000 x Years worked on site.]
The defense would then specify the range of ages and work histories which were to be sampled, and the court would choose plaintiffs within that range at random. Their cases would be tried, and the results used to calculate A.
In a more elaborate version, the plaintiffs' attorney would specify only the form of the model. An example might be:
Damages = A - B x Age in Years + C x Years worked on site+ D x (Years worked on site)2
The defense would again specify the characteristics of plaintiffs to be selected for trial, and the court would choose at random plaintiffs with those characteristics.
While both variants of this approach may sound complicated, especially to non-statisticians, their logic is the same as that of the simpler version described earlier. The difference is that the plaintiffs' attorney is providing a description of how damages relate to characteristics, rather than a claim for each plaintiff. The same logic as before makes it in his interest to get the description right. If, for example, he erroneously claims that the amount plaintiffs are entitled to does not depend on their age, when a jury would actually award more to younger plaintiffs, the defense can specify a sample heavily weighted towards older plaintiffs-and the result will be to push down the total amount awarded.
The same logic applies to more subtle errors. Suppose the plaintiffs' attorney specifies a linear relation of the form:
Damages = A + BL
where L is (say) length of exposure to asbestos. Further suppose that the real relation, the one that correctly predicts jury verdicts, is quadratic of the form:
Damages = A + BL2
The defense, if it recognizes the error, can specify a sample containing only small values of L. Again the result will be to push down the total verdict.
In each of these situations, just as with the simpler version of my proposed procedure discussed earlier, an inaccurate specification by the plaintiffs' attorney of the relative claims of different plaintiffs gives the defense an opportunity to reduce the total amount awarded, which in turn gives the plaintiffs' attorney an incentive to do an accurate job of specifying the relative claims.
So far I have assumed that the cases we are considering are ones where the plaintiffs seek money damages. The procedure can be generalized to any case with a quantitative award-one describable by some cardinal measure. An example would be a suit where the plaintiffs were employees claiming seniority.
Another assumption I have been making is that tort litigation under my procedure is always resolved by trial. What is the effect on the analysis if we include the possibility of settlement?
Even if there is some possibility of settlement, the plaintiffs' attorney still has an incentive to estimate the relative claims of the plaintiffs accurately. If the case goes to trial, inaccurate estimates will result in lower total damages, since the defense will select the overclaimed cases for trial. If the case settles, it will settle on less generous terms if the defense believes that the estimates are inaccurate, and the plaintiffs thus likely to do badly at trial.
So even when litigation leads to settlement, the procedure still provides a mechanism for allocating damage payments to plaintiffs that reflects the relative strength of their cases. By doing so, it should reduce the conflict among plaintiffs over settlement terms and so make settlement easier.
Suppose a judge wished to implement the procedure described in Part II above. What legal problems would he face?
To begin with, he would face the same problem faced in Cimino: the argument that due process required that each plaintiff have an opportunity to make his case in court, and that the defendant should have the opportunity to rebut each plaintiff's case. If, as in Cimino, the plaintiffs assented in advance to the procedure,[20] that argument should be no stronger here than there. If anything, the defendant's grounds for objection are even weaker under the procedure I have proposed. Insofar as the defense believes that some plaintiffs have weak cases-weaker cases, relative to other plaintiffs, than their claims indicate-the defense is free to select those cases for trial.[21]
If the plaintiffs, instead of or in addition to the defendant, object, the situation is somewhat more difficult. While the procedure saves the plaintiffs the cost of litigating every case separately, it also, for reasons I will discuss in Part IV, has some built-in bias against the plaintiffs. The plaintiffs might reasonably demand either that the procedure be modified to eliminate that bias (a possibility discussed below) or that they be compensated for accepting a biased procedure. Supposing that such objections were met, the plaintiffs under my procedure seem to be in the same situation as the defendants in Cimino; although their cases are not all being tried, they are being given an opportunity to get approximately the same awards they would get if they were tried, and at a much lower cost in litigation.
There is one respect in which the procedure is more defensible than that employed in Cimino-or, arguably, than the ordinary procedure for a class action. Rule 23(a)(4) of the Federal Rules of Civil Procedure requires that the representative parties in a class action will fairly and adequately protect the interests of the class. Under the procedure I have proposed, the representative parties have a clear interest in doing so. If they attempt to benefit themselves at the expense of other members of the class by arranging for their attorney to overclaim on their behalf, the defense will select their cases for trial.[22] The representative parties will gain nothing, and their attorney will have a lower total award out of which to compensate himself.
There are two fundamental problems with the procedure I have described. The first is that while it could produce a more accurate result at a much lower cost than would individual trials, it is not entirely clear that it will; it might instead produce a much more accurate result at a higher cost. The second is that the procedure, as so far described, has a built-in bias in favor of the defense.
The method incorporated into Phase III produces a level of economy in terms of both judicial resources and transaction cost that needs no elaboration.--Judge Parker in Cimino.
At first glance it seems obvious that trying 160 cases costs a great deal less than trying 2,298 cases, but this is not quite so clear as it seems. Under the procedure employed in Cimino, the verdicts in the tried cases determined the outcome for all of the other cases. The result is that the amount at stake in each tried case was about fourteen times as much as it would have been if each case had only determined the outcome for that plaintiff. With more at stake, we would expect both parties to spend more on trying to win.
Whether this eliminates the cost savings of fewer trials depends on how litigation expenditure varies with the amount at stake.[23] If the increase is proportional, the total cost of trials under either Cimino or the procedure I have suggested will be the same as if every case were tried separately; the only advantage of the procedure would then be the increased accuracy, due both to trying cases much more carefully and to using the average of the tried cases, rather than the result of one case, in calculating the amount to be awarded to each plaintiff.[24]
Suppose, however, that expenditure rises less than proportionally with the amount at stake, everything else held constant.[25] Under that assumption, expenditure on the tried cases becomes less and less important as the number of plaintiffs increases, since the larger the number of plaintiffs the smaller the fraction necessary to provide an adequate sample. In the limit of a very large number of plaintiffs, expenditure on trying the sample of cases is negligible compared to the cost of trying the cases individually. That is consistent with what actually happened in Cimino.
So far I have been considering a problem raised by both the Cimino procedure and the procedure I have proposed. There is an additional cost problem that applies only to the latter. Under that procedure, the plaintiffs' attorney spends resources estimating the relative claims of each plaintiff[26] and the defendant's attorney then spends resources examining plaintiffs in order to decide which cases to select for trial.
The plaintiffs' attorney can, if he wishes, produce his estimates of claims more accurately and less expensively than verdicts would be produced by individual trials. The same should be true for the defense attorney. In addition, if the number of cases is large, the defense need only examine a random sample of cases in order to do a reasonably good job of locating overclaimed cases to select for trial. It follows that the attorneys can act in a way which, under the proposed procedure, produces more justice at a considerably lower cost than would individual trials.
It is not, however, clear that it is in their interest to do so. Each attorney's objective, at least in part, is to benefit his clients at the expense of the other party. By making a more accurate set of estimates, the plaintiffs' attorney not only produces a more just distribution among his clients, he also makes it harder for the defense to locate overclaimed plaintiffs for trial. The more he spends on improving the accuracy of his claims, the larger the amount his side will receive. He must balance that benefit against the associated cost. The defense attorney faces a similar situation.
Here, as elsewhere in the economics of litigation, there is no reason to assume that the level of expenditure which is privately optimal for one party to a legal dispute is also socially optimal. The amount spent on estimating claims and detecting overclaimed plaintiffs will depend on detailed assumptions about information costs and distributions of claims, as we will see in the formal analysis presented in Appendix II and discussed in Part VI.
It follows from these arguments that we cannot be sure the procedure as described will cost less than ordinary trial without aggregation and sampling. This suggests two further queries. The first is whether we can say anything interesting about the relation between the costs of alternative approaches and the number of plaintiffs. The second is whether, if experience suggests that expenditures associated with the procedure are undesirably large, there may be ways of modifying it to reduce such expenditures.
An increase in the number of plaintiffs reduces the percentage of cases that must be tried. If expenditure per case increases less than proportionately with the amount at stake, the result is that trial costs for my suggested procedure (or the Cimino procedure) decrease, relative to the cost of trying all cases, as the number of plaintiffs increases.
The same is probably true for the cost to the defense of selecting cases for trial. The larger the number of plaintiffs, the smaller the fraction that must be sampled in order to find ten cases from (say) the most overclaimed five percent. We would expect defense expenditures to increase less than proportionally with the number of plaintiffs, and so become smaller and smaller, relative to the total amount at stake, as the number of plaintiffs increases. This result is demonstrated in Appendix II for the particular distributions assumed there.
The opposite result can be expected for the cost to the plaintiffs' attorney of calculating claims. The more plaintiffs there are, the easier it is for the defense to locate those who have overclaimed. The more accurately the defense can locate overclaimed plaintiffs, the greater the incentive for the plaintiffs' attorney to make accurate claims. So an increase in the number of plaintiffs will tend to increase the amount spent per plaintiff by the plaintiffs' attorney. That is one reason why it might be desirable to shift from individual claims to statistical models when the number of plaintiffs becomes sufficiently large. The per plaintiff cost of estimating the parameters of a model to a given accuracy will fall as the number of plaintiffs increases.
The size of the expenditures by the attorneys will depend on details of the distribution of claims and on the functions relating expenditure on investigating a claim to information produced. We cannot predict a priori how large it will be, any more than we can predict a priori, in the case of ordinary litigation, how much of the damages awarded will be eaten up in litigation costs. But if experience indicates that the attorneys are spending more than the improved accuracy their expenditure generates is worth, we can lower the amount they spend by a minor change in the procedure.
The incentive for the expenditures we (hypothetically) wish to reduce comes from their influence on the damages that will be awarded.[27] A court that wishes to reduce those expenditures can do so by selecting some cases for trial in the fashion I have described and some at random. The smaller the proportion of cases selected for trial by the defense, the lower the incentive that both attorneys have to spend more money estimating claims more accurately. Thus courts have a mechanism by which they can adjust the procedure to move its outcome closer to an optimal level of cost and accuracy. An alternative approach would be to try to impose limits on the amount each party was permitted to spend on evaluating claims.[28]
In the procedure as I have described it, the plaintiffs' attorney calculates claims and the defendant's attorney selects which will be tried: the former cuts and the latter chooses, to take the obvious analogy from the incentive-compatible procedure for dividing a piece of cake. Is there any good reason to do it this way, instead of requiring the defendant's attorney to list the amount he believes each plaintiff should receive and letting the plaintiffs' attorney choose which cases will be tried?
One reason is that the attorney who is calculating claims will need information from the plaintiffs which they might be reluctant to provide to the defense attorney, for fear that it would be used against them in trial. The procedure I have described does not eliminate this problem--the defense attorney still needs enough information to decide which cases to select for trial. But, if the group is large, he can do an adequate job by examining only a small subset of the plaintiffs, and can thus afford to spend much more per case examined than the plaintiffs' attorney. That should make it possible for him to produce a reasonably accurate estimate even with less cooperation from the individual plaintiff.[29]
The defense attorney is not the only one who must worry about being misled by individual plaintiffs. Plaintiff i gains by increases in Ci above <Di>, even though the plaintiffs as a group lose, so each plaintiff has an incentive, in dealing with his own attorney, to inflate his claim. A plaintiffs' attorney would presumably specify in his contract with the plaintiffs, whether representative plaintiffs in a class action or joint plaintiffs in an ordinary joint action, their obligations to furnish information that he requires in estimating their claims. Thus the procedure yields a contractual equivalent of discovery rules between the plaintiffs and their attorney. Although each plaintiff gains by his own ability to mislead his attorney, he loses by the ability of all other plaintiffs to do the same, so plaintiffs and their attorney have a common interest in agreeing to rules that will allow the attorney to make an accurate estimate of the strength of each plaintiff's case.
One consequence of having the plaintiffs' attorney cut and the defendant's attorney choose is to give the latter a cost advantage, at least in situations where the number of plaintiffs is large. As discussed earlier, the party who chooses can use random sampling to identify overclaimed cases at a relatively low total cost. This advantage may or may not outweigh the advantage that the plaintiffs' attorney has, due to the fact that the plaintiffs, who possess private information relevant to the strength of their cases, are his clients and have agreed to make such information available to him.
A second consequence is to give the defense an advantage in the final verdict. As I show in Appendix I, the defense can produce an expected total damage payment equal to the expected payment under a system of individual trials by simply selecting cases for trial at random, with probabilities proportional to Ci. By examining cases and selecting those that appear to be overclaimed, the defense should be able to improve on that result.
How significant these advantages are will depend on the details of the underlying factfinding technology-how accurately and at what cost each attorney can estimate <Di>. If the net advantage to the defense turns out to be large,[30] and if we wish neither to change the tort system in a way which advantages defendants in mass torts nor to give plaintiffs an incentive to avoid the procedure in favor of individual litigation, we could compensate by altering other legal rules applicable to the procedure in ways that advantage plaintiffs.
An alternative approach would be to eliminate the
bias by allowing both parties to cut and both to choose. Under such a
system, the plaintiffs' attorney produces a set of claims ![]() and
the defense produces a set of claims
and
the defense produces a set of claims ![]() .
Each attorney selects a set of cases to be tried. The court
calculates two values of R. Rp is calculated
using the plaintiffs claims and the verdicts of the cases selected by
the defense; Rd is calculated using the defense
claims and the verdicts of the cases selected by the plaintiffs'
attorney. Each plaintiff i receives the average of
Rp
.
Each attorney selects a set of cases to be tried. The court
calculates two values of R. Rp is calculated
using the plaintiffs claims and the verdicts of the cases selected by
the defense; Rd is calculated using the defense
claims and the verdicts of the cases selected by the plaintiffs'
attorney. Each plaintiff i receives the average of
Rp ![]() and
Rd
and
Rd ![]() .
This version of the procedure will cost more to produce a given level
of accuracy in the relative claims, since each is being calculated
twice. But it eliminates the bias in the outcome.[31]
It may or may not increase the total cost of the procedure. Since
each set of calculations plays only half the role it did before in
determining the amount actually awarded, the parties have an
incentive to spend less than before on increased accuracy. That may
or may not balance the increased cost of having each claim calculated
twice, and having each party try to identify cases that the other has
overclaimed.[32]
.
This version of the procedure will cost more to produce a given level
of accuracy in the relative claims, since each is being calculated
twice. But it eliminates the bias in the outcome.[31]
It may or may not increase the total cost of the procedure. Since
each set of calculations plays only half the role it did before in
determining the amount actually awarded, the parties have an
incentive to spend less than before on increased accuracy. That may
or may not balance the increased cost of having each claim calculated
twice, and having each party try to identify cases that the other has
overclaimed.[32]
My analysis so far has assumed that the procedure I am describing will be used, as the Cimino procedure was, in a class action. It might also be applied to an ordinary joint action with a large number of plaintiffs. The use of the procedure ought to make such a joint action easier to organize, since it provides a mechanism for solving the problem of allocating damages among the joint plaintiffs. After a putative mass tort had occurred, one or more lawyers would announce that he was forming a group of plaintiffs to litigate under the procedure; his announcement would includes the formula by which he would be reimbursed. Plaintiffs would be free to join his group, to join another group, or to litigate individually.
The procedure could also be used in situations other than class actions where a single agent already controls what are really multiple cases. One example would be disputes between insurance companies, each of which controls a large number of legal claims for accidents involving its customers. In that context, the procedure would be a way of guaranteeing to each customer that the insurance company was fairly representing his interests in the litigation.
The procedure would be inappropriate if the agent who controlled multiple cases also fully owned them. Such an agent would care about the total awarded to all of the cases he owns, not the distribution among them. The Cimino procedure would give the correct total at a lower cost than the procedure discussed here. Such a situation could occur in the insurance context. It might also arise if, as some writers have suggested, tort claims were made fully marketable, allowing legal entrepreneurs to buy up large numbers of related claims and litigate them en masse.33 Under such institutions the damage award would reach the victim in the form of the price for which he sold his claim, so the distribution among victims would be determined by the market rather than directly by the court.
Appendix II presents a formal model, based on an error distribution that is bounded and uniform. I demonstrate that, as the number of cases goes to infinity, the defense is able to perfectly identify overclaimed cases at a cost that is vanishingly small relative to the amount at stake. The plaintiffs maximize their net return by spending the same amount in investigating each case and claiming an amount equal to their estimate of the expected return at trial.
The result becomes more complicated if we assume that some cases are more difficult to evaluate than others. The optimal strategy is then to estimate those cases less accurately, insuring against the risk that the resulting estimate may be too high by deliberately claiming less than their estimated value.
Several further points are worth noting about this situation. The first is that cases that are difficult for the plaintiffs' attorney will also be difficult for the defense attorney, so the defense has an incentive not to examine those cases. The lower the probability that a certain sort of case will be examined, the less the risk of overclaiming for such cases, so this effect will work in the opposite direction from that demonstrated in the model.[34]
A second point arises if plaintiffs are risk averse. Cases that are difficult for the attorneys are also difficult for the court, so plaintiffs with hard cases face a bigger gamble if they go to court individually, and thus gain more by replacing that gamble with the more certain outcome generated by the procedure I have proposed. In addition, hard cases are likely to be more expensive to litigate, again making the procedure particularly attractive as a substitute for individual trial to plaintiffs with hard cases. So even if the procedure gives plaintiffs with hard cases somewhat less than their expected return at trial, that may not make them less willing to join the class than plaintiffs with easy cases.
If, despite these considerations, the incentive to underclaim hard cases turns out to be a serious problem, it can be dealt with in the same way earlier suggested for dealing with the procedure's pro-defense bias. The analysis of strategies with regard to hard cases is symmetrical; if the defense cuts and the plaintiffs' attorney chooses, the defense has an incentive to overclaim hard cases. So if both parties cut and both choose, the biases will tend to cancel.
One important limitation of the formal model of
Appendix II is that its error distributions are bounded. The result
is that, as the number of cases increases, the additional gain to the
defense of more and more accurately identifying the overclaimed cases
becomes less and less; there are no cases to be found that are
overclaimed by more than a factor of 1+![]() p.
If the error distribution for the plaintiffs' estimates is unbounded,
and if the defense can make the error of its estimate as small as it
likes by spending enough money examining enough cases, it is in the
interest of the defense to push R further and further down the
larger the number of cases, so that in the limit of an infinite
number of cases damages awarded would go to zero.
p.
If the error distribution for the plaintiffs' estimates is unbounded,
and if the defense can make the error of its estimate as small as it
likes by spending enough money examining enough cases, it is in the
interest of the defense to push R further and further down the
larger the number of cases, so that in the limit of an infinite
number of cases damages awarded would go to zero.
How serious a problem this is likely to be with plausible numbers of cases and error distributions is an empirical issue. If it does turn out to be a problem, it might be controlled by any of several modifications to the procedure suggested earlier.
I have proposed a procedure which has the potential to settle mass torts at a cost much less than individually litigating each claim. Like the Cimino procedure, it produces about the same outcome for the defense as would individual trials. Unlike the Cimino procedure, it provides outcomes for the individual plaintiffs tailored to the strength of their individual cases; indeed, it may well produce a more accurate allocation of damage payments to plaintiffs than would individual trials.
One can imagine applying the procedure in a variety of different contexts. In a case such as Cimino v Raymark, where there are a large number of plaintiffs each with a substantial claim, individual attorneys might compete to form groups to litigate under the procedure, thus avoiding some of the usual problems with class actions. Where individual claims were smaller, the class could be formed in the usual way; the procedure[35] would then provide a way of allocating damages among plaintiffs. By reducing the risk that the plaintiffs' attorney would sacrifice the interests of the plaintiffs in general to his own interest and that of the representative plaintiffs, the procedure makes it more likely that a class would, and should, be certified in such situations.
The procedure is not perfect; it provides no guarantee of an optimal expenditure on evaluating cases in order to allocate damages. This is equally true of alternatives, including the alternative of litigating each case separately. Also, although the plaintiffs' attorney will find it in his interest to make his claims roughly proportional to the strength of the individual cases, the relation will not be exact; differences in the difficulty of evaluating cases may, as demonstrated in the formal model, make it in his interest to deliberately underclaim some cases relative to others.[36] Finally, the simpler versions of the procedure are to some degree biased in favor of the defense, since the plaintiffs cut and the defense chooses. If such problems prove serious, there are ways in which the procedure can be modified to reduce them.
Suppose we are dividing a cake under the conventional rule of "I cut, you choose." Further suppose that we have identical tastes; each of us prefers the larger slice. It seems obvious that, if there is any inaccuracy in cutting cakes, the party who moves second has the advantage. One way of seeing this is to note that if he selects his slice at random he will, on average, get half the cake; if he has any ability at all to recognize the larger piece, he will do better than that. An analogous argument implies that, under the procedure described in this article, the defense can always do at least as well as it would with individual trials, and may be able to do better. The analysis goes as follows:
Suppose that, instead of examining cases and trying to select the ones that are overclaimed, the defense simply selects cases by a random process, with a probability
pi = ![]() of
selecting case i. We then have:
of
selecting case i. We then have:
Expected total damage payment = <R> x Total Claims
= ![]() =
= 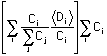 =
=![]()
= Expected total damage payment with individual trials.
So a random procedure, with no examination at all, produces as good a result for the defense as individual trials. By selecting cases that are overclaimed, the defense can get a better result than that-a lower expected total damage payment-at some cost. If the cost is less than the gain, the defense does better under this procedure than with individual trials. If the cost is greater than the gain for all levels of expenditure on examining cases, the defense follows the strategy described above and does as well as it would with individual trials.
There are N plaintiffs. Each plaintiff
i has an expected result at trial di. This
is the same as <Di> in the earlier
discussion. The distribution of di is described by
a probability density ![]() (d)
and is the same for all i. Its expected value is
<d>. All parties are risk neutral, so the plaintiffs'
attorney is trying to maximize expected damage payments net of
expenditures on investigating cases (in order to decide how much to
claim for each) and litigating them, while the defense attorney is
trying to minimize expected damage payments plus defense expenditures
on investigating cases (in order to select some for trial) and
litigating them. Nt cases will be selected for
trial by the defense.
(d)
and is the same for all i. Its expected value is
<d>. All parties are risk neutral, so the plaintiffs'
attorney is trying to maximize expected damage payments net of
expenditures on investigating cases (in order to decide how much to
claim for each) and litigating them, while the defense attorney is
trying to minimize expected damage payments plus defense expenditures
on investigating cases (in order to select some for trial) and
litigating them. Nt cases will be selected for
trial by the defense.
Either attorney can generate an estimate of di by spending an amount Ei investigating that plaintiff's case. The value of the estimate will be:
![]() =di(1+ei).
(Equation 1)
=di(1+ei).
(Equation 1)
Here ei is a random error,
uniformly distributed between -![]() (Ei)
and +
(Ei)
and +![]() (Ei).
(Ei).
The more the attorney spends on investigating the case, the more accurate the estimate:
![]() <
0. (Assumption 1)
<
0. (Assumption 1)
Investigation is subject to diminishing returns-additional expenditures yield less and less reduction in error:
![]() >
0. (Assumption 2)
>
0. (Assumption 2)
There is no limit to how accurate the investigation can be, if the attorney is willing to spend enough-he could, for example, stage repeated dummy trials. So:
![]() =
0. (Assumption 3)
=
0. (Assumption 3)
Finally, I assume that the prior distribution
![]() (d)
is sufficiently flat and
(d)
is sufficiently flat and ![]() (Ei)
sufficiently small so that the conditional distribution
(Ei)
sufficiently small so that the conditional distribution ![]() (di
|
(di
|![]() )
is essentially uniform between di =
)
is essentially uniform between di = ![]() /(1+
/(1+![]() (Ei))
and di=
(Ei))
and di= ![]() /(1-
/(1-![]() (Ei))[37]
(Ei))[37]
My objective is to describe a Nash equilibrium, a pair of strategies such that each party's strategy is optimal against the strategy of the other party. I will start by deriving the plaintiffs' strategy in the limit of large N, then derive the defense strategy in the general case, then use that argument to derive the plaintiffs' strategy in the general case. My objective is to provide something more than a sketch but short of a full blown proof; I will not, for example, demonstrate that the solution I offer is unique.
The
Plaintiffs' Strategy: The Limit of Large NConsider the
situation from the standpoint of the plaintiffs' attorney deciding
how much to spend examining each case. He plans to spend an amount
Ei examining each case i, then make a claim
Ci based on ![]() ,
the estimate of di he produces. How much should he
spend on each case, and how should he then calculate
Ci ?
,
the estimate of di he produces. How much should he
spend on each case, and how should he then calculate
Ci ?
As N goes to infinity, the defense, as we will see below, can perfectly identify the most overclaimed cases,[38] so the cases selected for trial will be those for which di /Ci is minimal.
The plaintiffs' attorney wishes to maximize the net gain to his clients. Since the number of cases being tried is determined by the rules of the procedure, not by the attorneys, we take expenditure for trial as fixed.[39] So the attorney minimizes:
Damage payment received - expenditure on examination
= ![]() =
=![]() .
.
Where Di is the verdict from a jury trial of case i, and {t} is the set of cases tried. Averaging this over many trials, and taking advantage of the fact that di=<Di>, we have:
Expected value of damages - expenditure on examination
= ![]() = Net Benefit to Plaintiffs = nbp.
= Net Benefit to Plaintiffs = nbp.
In the large number situation, we can think of the
cases as grouped; each group contains cases with common
values[40]
of Ei, ![]() and Ci. As N goes to infinity, the number of
cases in each group expands without limit. The defense can then
select, if it wishes, Nt cases from those within a
group, each of which has the minimal value of di
/Ci . It follows that all that matters about a
group, so far as its effect on R is concerned, is
Ri, defined as the minimal value of
di/Ci for cases in the group.
Under our assumptions, the lowest value of di
consistent with a given pair
and Ci. As N goes to infinity, the number of
cases in each group expands without limit. The defense can then
select, if it wishes, Nt cases from those within a
group, each of which has the minimal value of di
/Ci . It follows that all that matters about a
group, so far as its effect on R is concerned, is
Ri, defined as the minimal value of
di/Ci for cases in the group.
Under our assumptions, the lowest value of di
consistent with a given pair
( ![]() ,Ei)
is
,Ei)
is ![]() /(1+
/(1+![]() (Ei)),
so Ri=[
(Ei)),
so Ri=[ ![]() /Ci][1/(1+
/Ci][1/(1+![]() (Ei))].
(Ei))].
Imagine that there are two groups, i and j, such that Ri>Rj. Since the defense is trying to make R as low as possible, cases from group i will not be selected for trial. So the plaintiffs' attorney can reduce his expenditure without lowering expected damage payments by lowering Ei. It follows that, if nbp is being maximized, Ri=Rj for every pair i,j. It follows that (still in the limit of large N)
Ri=[ ![]() /Ci][1/(1+
/Ci][1/(1+![]() (Ei))]=R.
(Ei))]=R.
Since Ei is chosen and spent
before ![]() is observed, the plaintiffs' attorney does not have the option
of making Ei depend on
is observed, the plaintiffs' attorney does not have the option
of making Ei depend on ![]() .
He could, however, use different values of Ei for
different cases, and for each observed
.
He could, however, use different values of Ei for
different cases, and for each observed ![]()
set
Ci=[ ![]() /R][1/(1+e(Ei))]
(Equation 2)
/R][1/(1+e(Ei))]
(Equation 2)
thus making Ri=R.
Averaging over many repetitions of the trial, and taking advantage of
the fact that the average value of ![]() is di and the average value of
di is <d>, yields
is di and the average value of
di is <d>, yields
<nbp>= ![]() .
(Equation 3)
.
(Equation 3)
There is some value of Ei that maximizes the expression
![]()
;
call that value E*. We have, for E=E*:
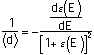 .
(Equation 4)
.
(Equation 4)
The plaintiffs' attorney maximizes the net
expected return for his clients by setting
Ei=E* [universal]i. Having
done so, Ci=[ ![]() /R][1/(1+
/R][1/(1+![]() (E*))]
[universal]i, so Ci is proportional
to
(E*))]
[universal]i, so Ci is proportional
to ![]() .
As pointed out earlier, the optimal values for Ci
are arbitrary up to a multiplicative constant, here represented by
R. For simplicity we may set R=1/(1+
.
As pointed out earlier, the optimal values for Ci
are arbitrary up to a multiplicative constant, here represented by
R. For simplicity we may set R=1/(1+![]() (E*)),
making Ci=
(E*)),
making Ci= ![]() .
.
The Defense
StrategyWe retain assumptions 1-3 above. We further assume that the
plaintiffs' strategy is as described earlier; Ci=
![]() ,
Ei=E*, [universal]i. In order
to avoid confusion between variables corresponding to plaintiffs and
defense, we relabel E* as Ep,
,
Ei=E*, [universal]i. In order
to avoid confusion between variables corresponding to plaintiffs and
defense, we relabel E* as Ep, ![]() (E*)
as
(E*)
as ![]() p.
We are now free to use Ei, ei to
refer to defense expenditures and defense errors.
p.
We are now free to use Ei, ei to
refer to defense expenditures and defense errors.
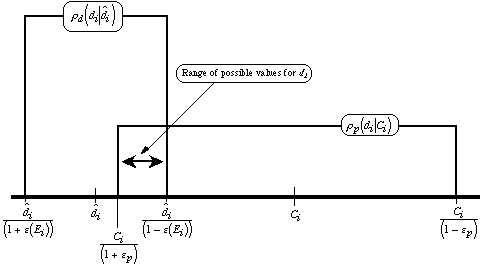
Figure 1
Suppose the plaintiffs have made a claim
Ci for case i. The defense spends
Ei to estimate di and gets a
value ![]() .
Figure 1 shows the situation, including the probability distributions
for di implied separately by the observations of
plaintiffs and defense. The implication of these two distributions is
that di is distributed uniformly between
Ci/(1+
.
Figure 1 shows the situation, including the probability distributions
for di implied separately by the observations of
plaintiffs and defense. The implication of these two distributions is
that di is distributed uniformly between
Ci/(1+![]() p),
the lowest value consistent with the plaintiffs' estimate, and
p),
the lowest value consistent with the plaintiffs' estimate, and
![]() /(1-
/(1-![]() (Ei)),
the highest value consistent with the defense estimate. It follows
that the expected value of di/Ci,
conditional on Ci and
(Ei)),
the highest value consistent with the defense estimate. It follows
that the expected value of di/Ci,
conditional on Ci and ![]() ,
is
,
is
![]() (Equation
5a)
(Equation
5a)
if ![]()
and
![]() (Equation
5b)
(Equation
5b)
otherwise.
Next consider the distribution of outcomes that
the defense can expect from spending Ei examining a
case i. The situation is shown in Figure 4. Here ![]() p
is the probability distribution for di given
Ci;
p
is the probability distribution for di given
Ci; ![]() d
is the probability distribution for
d
is the probability distribution for ![]() given Ci.
given Ci.
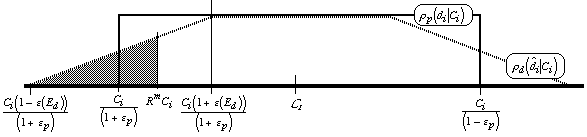
Figure 2
Suppose the defense wishes to examine a number of
cases Nd in order to select Nt of
them for trial, spending Ed on each case examined.
In order to minimize <R>, it is sufficient (from
Equations 5a,b) to choose the Nt cases for which
![]() is lowest. This corresponds, on Figure 2, to picking the shaded
region under
is lowest. This corresponds, on Figure 2, to picking the shaded
region under ![]() d
, with area
Nt/Nd.[41]
Here Rm is the maximum ratio of
d
, with area
Nt/Nd.[41]
Here Rm is the maximum ratio of ![]() selected for trial, and depends on
Nt/Nd and
Ed.
selected for trial, and depends on
Nt/Nd and
Ed.
Suppose that, as shown,
Rm < ![]() .
.
We then have, with a little manipulation:
![]() .
(Equation 6)
.
(Equation 6)
Where the expected value, here and below, is taken over the cases selected for trial. Combining Equation 5a with Equation 6, we have, for a given value of Rm:
![]()
![]()
. (Equation 7)
We also have, with a little more manipulation:
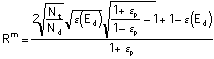 .
(Equation 8)
.
(Equation 8)
Substituting Equation 8 into Equation 7 gives us:
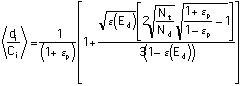
=<R>.
The defense chooses Nd, Ed to minimize:
Expected Damage payments plus expenditure examining cases
=<R> ![]() +NdEd=<R>N<d>+NdEd
+NdEd=<R>N<d>+NdEd
= 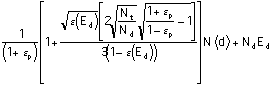 .(Equation
9)
.(Equation
9)
Setting the derivatives wrt Nd and Ed equal to zero gives us:
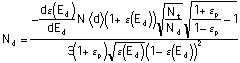 (Equation
10a)
(Equation
10a)
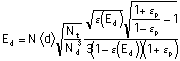 .
(Equation 10b)
.
(Equation 10b)
Combining the last two equations and solving for Nd yields:
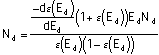
.
From which it follows that:
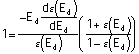 .
(Equation 11)
.
(Equation 11)
The solution to equation 11 is a value
Ed* independent of N. Since the plaintiffs
must examine every case, it never pays them to spend more than
<d> on each; so as N goes to infinity,
Ep goes to some upper limit and ![]() (Ep)
goes to some limit >0. Combining these facts with Equation 10a
implies that, for sufficiently large N, Nd
increases as N O.
(Ep)
goes to some limit >0. Combining these facts with Equation 10a
implies that, for sufficiently large N, Nd
increases as N O.
Hence:
![]()
![]()
As the number of cases goes to infinity, the defense perfectly identifies overclaimed cases at a cost that is vanishing small compared to the amount at stake. This confirms the verbal analysis earlier used to derive the plaintiffs' strategy in the limit of large N.
The Plaintiffs' Strategy: Finite NWe can use our results for the defense to learn more about the plaintiffs' strategy for finite N.[42] The equivalent of Equation 8, seen from the plaintiffs' side, is:
Net Benefit to Plaintiffs
= 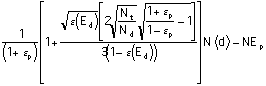 .
.
Here Ep is the expenditure by the plaintiffs on examining each case. The Plaintiffs maximize their net benefit by choosing Ep:
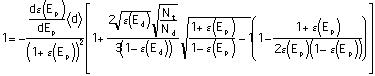
In the limit as N goes to infinity, this
gives us back Equation
4.Some
ComplicationsWe have assumed, so far, that all cases are identical ex
ante. Suppose we instead assume that there are two sorts of cases:
easy cases and hard cases. For easy cases, the distribution of error
is ![]() e(E);
for hard cases it is
e(E);
for hard cases it is ![]() h(E).
h(E).
![]() e(E)
<
e(E)
< ![]() h(E)
[universal]E.
h(E)
[universal]E.
The argument implying that
Ri=R [universal]i still holds
under this assumption, but the plaintiffs' attorney no longer
maximizes his clients' expected net benefit by using the same value
of Ei for each client and making claims
Ci proportional to ![]() .
Instead, he applies Equation 4 separately to calculate
Ee, Eh. Ci is
then calculated from Equation 2, using Ee for the
easy cases and Eh for the hard
cases.
.
Instead, he applies Equation 4 separately to calculate
Ee, Eh. Ci is
then calculated from Equation 2, using Ee for the
easy cases and Eh for the hard
cases.
In my earlier verbal analysis, I asserted that the plaintiffs' attorney would find it in his interest to make his claims proportional to his estimate of the strength of each case. We now see that this conclusion must be qualified. If some cases are known to be more difficult than others, meaning that it is more costly to estimate the average verdict if they are tried, the plaintiffs' attorney has an incentive to hold down his costs by making a less accurate estimate for those cases, and make up for it by somewhat underclaiming them.
[*] John M. Olin Law and Economics Fellow, University of Chicago. I would like to thank my colleagues at the University of Chicago and Cornell Law Schools, especially Jonathan Macey, Geoffrey Miller, and Richard Posner, for many helpful suggestions.
[0]751 F.Supp. 649, Claude Cimino, et al. v. Raymark Industries, Inc., et al.
[1]Michael J. Saks & Peter David Blanck, "Justice Improved: The Unrecognized Benefits of Aggregation and Sampling in the Trial of Mass Torts," Stan L. Rev. 44 (1992) 815-851.
[2]This assumes, of course, that the cases would have been tried. As Judge Parker pointed out in his opinion, the defendants "assert a right to individual trials in each case and assert the right to repeatedly contest in each case every contestable issue involving the same products, the same warnings, and the same conduct. The strategy is a sound one; the defendants know that if the procedure in Cimino is not affirmed, these cases will never be tried."
[3] The issues were whether each asbestos containing insulation product manufactured by each defendant, settling and non-settling, was defective and unreasonably dangerous, the adequacy of warnings, the state of the art defense and the fiber type defense. The question of punitive damages in the entire case of the 2,298 class representatives was also submitted for jury determination.
[4]Phase II was resolved by stipulation by the parties.
[5]The increase in sample size was less than proportional, as one would expect if the objective was to get equally reliable results for each category. The opinion states that "When setting the sample size for each disease category, the Court sought a confidence level of 95%, in other words +- 2.00 standard deviations." The numbers (samples of 50 each for two categories with 1,050 and 972 plaintiffs) suggest that the court did not apply any very precise statistical rule.
[6]Judge Parker's statement that "Defendants complain about the 1% likelihood that the result would be significantly different" suggests that he interprets a 99% confidence level as a probability of 99% that the procedure will yield a result within some (unspecified) significant error--where "significant" means "important" not "statistically significant."
Whatever error he did use, what ought he to have used? One possibility would be to compare the procedure to the result of individual trials, taking account of the difference in litigation costs. Suppose, for example, that aggregation saves the defense a million dollars in legal expenses. One might then ask how likely it is that the award is more than a million dollars greater than what would have been awarded if all cases were tried. If the answer is .01, there is then only one chance in a hundred that the procedure has made the defendants worse off. While that approach solves the problem of picking an appropriate error, it still leaves the problem that statistics cannot generate such probabilities without making assumptions about the characteristics of the sample.
[7] "Individual members of a disease category who will receive an award that might be different from one they would have received had their individual case been decided by a jury have waived any objections." Judge Parker in Cimino.
[8]The opinion discusses under what circumstances smoking would constitute contributory negligence and notes that some plaintiffs received awards of zero, but does not say whether any received zero awards for that reason.
[9]Federal Rules of Civil Procedure 23a(4).
[10]Suppose the court uses an aggregation process that awards every plaintiff the average of what all plaintiffs in the class are entitled to. Plaintiffs who can expect an above average return withdraw from the class. That lowers the average that the remainder can expect to get, causing more plaintiffs to withdraw. Under some circumstances, the entire class may come apart in this way. This is a form of adverse selection, more familiar in the context of insurance. See G. Akerlof, "The Market for `Lemons'," Vol. No. 336 QJE 488-500 (1970).
[11]It was permitted in Daar v. Yellow Cab Co., 67 Cal. 2d 695, 433 P.2d 732, 63 Cal. Rptr. 724, rejected by the Second Circuit in Eisen v. Carlisle and Jacquelin, 479 F. 2d 1005, and has not been ruled upon by the Supreme Court.
[12]Stan. L. Rev. 44 (1992) 851. "Collective Justice in Tort Law," by Glen O. Robinson & Kenneth S. Abraham, 78 Va. L. Rev. suggests and discusses several other statistical approaches to dealing with mass torts, using information from the outcomes of similar cases to determine, or at least affect, awards.
[13]As Saks and Blanck point out, average jury awards seem to increase less than linearly with the amount of injury suffered by the plaintiff (Stan. L. Rev. 44 (1992) p. 840).
[14]In explaining my proposed procedure, I assume that it is being applied to a case with many plaintiffs and one defendant; the application to the less common case of one plaintiff and many defendants should be straightforward.
[15]One reason such rules are necessary is that the decision-maker in a trial has only weak incentives to reach the correct decision, and can therefore not be trusted to do unless severely constrained. Under the proposed procedures, it is in the private interest of the decision maker (the plaintiffs' attorney) to estimate the strength of claims accurately, making such constraints less necessary.
[16] The plaintiffs attorney can achieve the same objective by attempting to set Ci proportional to <Di>: Ci=K<Di>, where K is some constant. The value of K has no effect on the outcome; R, on average, will be 1/K, so plaintiffs will receive RxCi=<Di>, independent of K. I therefore assume K=1 for simplicity in exposition.
[17]As we will see later, this statement is only approximately true. If some cases are harder to evaluate than others, the optimal strategy for the plaintiffs' attorney may deviate somewhat from that described here.
[18]This is one of the central points made by Saks and Blanck in defending the Cimino procedure. Stan. L. Rev. 44 (1992) pp. 833-836.
[19]Stan. L. Rev. 44 (1992) 851.
[20]Since the class was certified before the procedure was proposed, the assent was presumably by the representative plaintiffs controlling the litigation rather than by the unanimous decision of all plaintiffs. But the procedure created a conflict of interest among members of the class, which arguably called into question the ability of the representative plaintiffs to represent the interests of the remaining plaintiffs.
[21]For an extensive discussion of legal issues associated with aggregation, see "Collective Justice in Tort Law," by Glen O. Robinson & Kenneth S. Abraham, 78 Va. L. Rev.
[22]If it is not obvious that they are overclaiming, the defense may miss some of their cases, in which case some of the overclaimed representative defendants will get more than they should. On the other hand, given that possibility, one would expect the defense to take special care in examining the claims made for the representative plaintiffs. I am assuming here that plaintiffs whose cases are actually tried get the amount awarded to them, rather than having their award calculated from their claim in the same fashion as plaintiffs whose cases are not tried. Without that assumption, representative plaintiffs gain by overclaiming even if they are sure their cases will be among those tried--although the attorney for the class of plaintiffs loses, if his recompense is an increasing function of the total amount awarded.
[23]I do not know of any definitive analysis of this question. One possible approach would be to assume Nash equilibrium. S is the amount at stake. The probability that the plaintiff will win the case depends on expenditures Lp (by the plaintiff) and Ld (by the defendant): P(Lp,Ld). The parties increase their expenditures until they reach the point where a one dollar increase in expenditure by the plaintiff increases his expected return (P(Lp,Ld) S) by one dollar, and a one dollar increase in expenditure by the defendant increases his expected return (-P(Lp,Ld) S) by one dollar:
![]()
![]()
Under these assumptions, the question of how
expenditure increases with amount at stake becomes the question of
how rapidly ![]() decreases
as Lp and Ld increase. If, for
example,
decreases
as Lp and Ld increase. If, for
example,
![]() ,
,
then expenditure increases more (less) than in proportion to the amount at stake if b<1 (b>1).
One objection to this approach is that Nash equilibrium is not very plausible in a game involving only two parties, and still less plausible in a situation where the two parties can and do bargain with each other.
[24]In the case of the Cimino procedure, that must be balanced against the decreased accuracy from awarding plaintiffs whose cases are not selected for trial average verdicts even though the particular plaintiff may not have average characteristics.
[25]The comparison is between two cases whose only difference is the amount at stake; each of my ten cases is simply one of the thousands of cases that might be tried individually. I am not assuming that the ratio of litigation cost to the amount at stake for the typical large case is smaller than for the typical small case; presumably the typical large case not only has more at stake but also a more complicated set of legal and factual issues than the typical small case.
[26]Or spends resources determining how the amount a plaintiff is entitled to is related to the plaintiffs characteristics, under the alternative version that I proposed for cases with very large numbers of plaintiffs and small average claims.
[27]It is possible that the plaintiffs' attorney may have additional incentives, due to concerns with either justice or risk among his clients. They might prefer that claims be proportional to the actual injury each client has suffered, even if claims did not affect the total amount paid out.
[28]In a class action, a judge could limit expenditure by one side simply by limiting the expenses he was willing to permit the class attorney to claim. Limiting expenditure by the other party, or by both parties if the procedure was being used outside of a class action, would be more difficult.
[29]Presumably there would be legal rules requiring some cooperation from the plaintiffs. "(M)ost courts have taken the view that reasonably necessary discovery against individual class members should be allowed as a matter of judicial discretion, but that discovery is not allowable of right as it would be against a party to a nonclass suit. (e.g. Brennan v. Midwestern United Life Ins. Col, 450 F.2d 999 (7th Cir. 1971)."Civil Procedure, 3d ed, Fleming James Jr. and Geoffrey C. Hazard, Little, Brown and Co. Boston, Toronto 1985 p. 579.
[30]This does not require the defense attorney to be better at estimating <Di> than the plaintiffs' attorney, as should be clear from the analysis above. If, for example, accurate estimates are very expensive and the number of plaintiffs is large, the plaintiffs' attorney will produce very inaccurate estimates and the defendant's attorney, spending much more per case on a small fraction of the cases, will be able to find cases that are greatly overclaimed, thus greatly reducing the total amount paid out in damages.
[31]That conclusion depends on assuming that both sides are equally able to generate the relevant information. If, as suggested earlier, the plaintiffs' attorney has better access to information about plaintiffs, the version of the procedure described here is biased in favor of the plaintiffs. If one knew how great the informational advantage was, one could compensate for it by using an appropriately weighted average of the awards calculated from the two different sets of claims.
[32]If we assumed that each party aimed at the same level of accuracy as under the earlier version of the procedure, expenditure would be increased but not doubled by requiring each party to both cut and choose. The information generated in cutting can also be used in choosing. The defense attorney's first step in identifying overclaimed cases will be to compare the plaintiffs' attorney's claims with his own.
[33]For discussions of the idea of marketable claims, see Marc J. Shukaitis, "A Market in Personal Injury Tort Claims," XVI J.L.Stud. pp. 329-349 (June 1987), David Friedman, "Private Creation and Enforcement of Law-A Historical Case," VIII J.L.Stud. (March 1979), pp. 399-415, David Friedman, "What is Fair Compensation for Death or Injury?" IRLE 2 (1982), pp. 81-93, Jonathan Macey and Geoffrey Miller, "The Plaintiffs' Attorneys Role in Class Action and Derivative Litigation: Economic Analysis and Recommendations for Reform.," U. Chi. L. Rev. 58 (Winter 1991) pp. 1-118.
[34] That is not true for the formal model of Appendix II in the limit of large N, because in that situation the defense is able to perfectly identify overclaimed cases at negligible cost.
[35]Possibly the statistical version discussed above.
[36]I have presented this as a fault of the procedure, but it could be viewed as a desirable consequence. It may be desirable, on grounds of either efficiency or justice, for parties who insist on litigating difficult cases to bear part or all of the cost of doing so. Underclaiming difficult cases costs plaintiffs less than estimating the strength of their case as accurately as easy cases are estimated. Thus this feature of the procedure has consequences similar to those of the usual (American) rule that each party must bear his own litigation costs: plaintiffs with cases that are expensive to litigate take home less, net of litigation costs, than parties who have suffered similar damage but have easy cases..
[37]The reason we need to assume a sufficiently flat prior in order for this to be true is that the conditional probability will depend both on the distribution of the error and on the prior distribution, in a fashion described by Bayes' theorem. The reason we must assume that e(Ei)<<1 is that otherwise a uniform distribution of e will not give something close to a uniform distribution of 1/(1+e). As should become clear, these are simplifying assumptions designed to keep the formal analysis manageable, not likely to have much effect on the (qualitative) results.
[38]More precisely, the defense can identify the most overclaimed cases that exist with positive probability. There could be (say) a single case that was overclaimed by more than any other but that the defense missed because it was not in the sample examined. As N goes to infinity, the probability and hence the effect on average damages collected of any single case goes to zero. Any kind of case with positive probability will be represented an infinite number of times in the total (as N goes to infinity), and thus will be included in the sample selected for examination by the defense.
[39]The strategy followed in selecting cases might have some effect on the two sides' incentives to spend money litigating them. Since I have no theory of litigation expenditures, and in any case expect them to become insignificant relative to the total amount at stake when N becomes sufficiently large, I ignore this possibility in the analysis.
[40]Or, more precisely, a narrow range of values. As N goes to infinity, we can make the range as narrow as we wish.
[41]The defense is ignoring Ci in picking cases to examine since, as we see by Equations 6 and 7, it can get the same <R> out of each level of Ci by picking the same fraction of each. The analysis is being done for a particular value of Ci, but applies to every value.
[42]This is not a full analysis, since I have not redone, for finite N, the proof that the plaintiffs spend the same amount on every case and choose claims proportional to the estimated strength of each case.
Back to my home page.